동행 (AI 국가유산 해설사), ssafy x kakaotech Hackathon

ssafy x kakaotech Hackathon ( 2026.06.13 ~ 06.14 )
- 10대 민생 프로젝트 해결과제 (문화유산)
Team: 행동 ( 조일민, 김민제, 권오준, 이용우, 강창룡 )
서비스 소개 영상
시연 영상





2년 전 카카오테크에서 함께했던 동생들에게 해커톤에 같이 참가하지 않겠냐는 연락을 받았었다. 오랜만에 대회도 나가보고 싶었고, 새로운 자극도 필요하다는 생각이 들었던 시기라 크게 고민하지 않고 참가를 결정했다. 결과부터 말하자면, AI의 발달로 꽤나 많은 개발자들이 위기감, 우울감에 빠져있는걸 볼수 있는데, 그 속에서 나는 어떠한 개발을 좋아하고 앞으로 나아가야 할 방향을 다시 한번 생각해볼 수 있었던 시간이었다.


평소 회사에서는 텍스트 중심의 챗 서비스 오케스트레이션을 개발하고 있다. 그러다 보니 자연스럽게 텍스트 기반의 서비스에 익숙해져 있었는데, 이번에는 음성과 이미지를 활용하는 서비스를 만들게 되면서 조금 다른 관점으로 접근할 수 있었다. 개인적으로도 앞으로 AI 서비스는 텍스트를 넘어 음성과 이미지가 함께 활용되는 형태가 점점 많아질 것이라고 생각해왔는데, 직접 구현해보니 생각보다 더 재미있었고 나에게도 좋은 리프레시가 되었다.
현재 회사에서 주로 다루는 POST/gRPC 프로토콜이나 텍스트 중심의 아키텍처를 넘어, 차후에 메인 스트림이 될 거라고 믿고 있는 음성과 이미지 중심의 멀티모달 서비스를 밑바닥부터 설계해볼 수 있었던 게 가장 큰 수확이었다. 특히 단순 인터페이스의 변화를 넘어 WebRTC를 활용한 실시간 스트리밍 환경에서 레이턴시와 서비스 안정성을 어떻게 확보할 것인가에 대해 새로운 관점으로 접근해볼 수 있었던 경험이 참 값졌다.
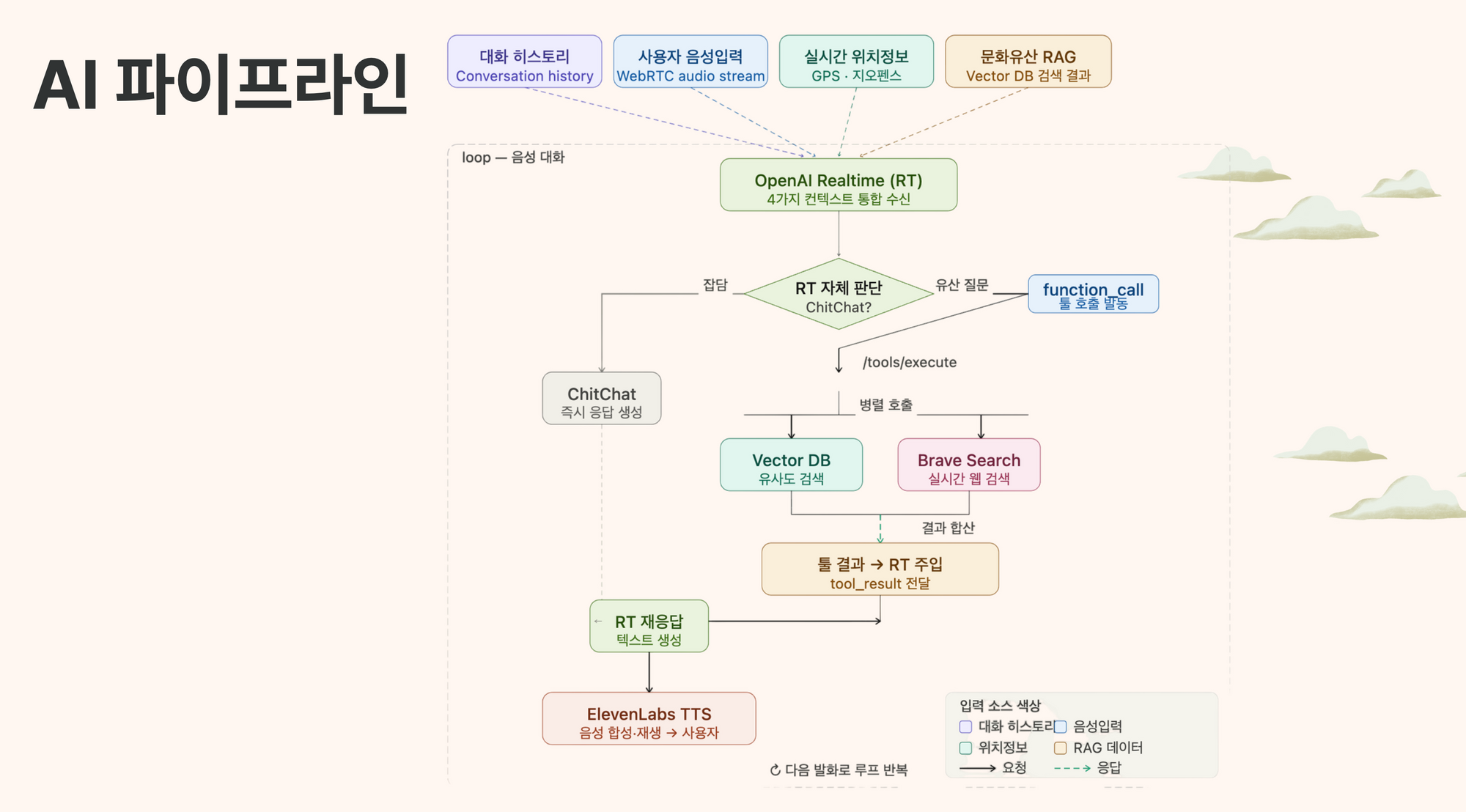
이 과정에서 AI를 잘 활용한다는 게 무엇인지에 대한 고민도 깊어졌다. AI 서비스에서 중요한 것은 모델뿐만 아니라 모델을 둘러싼 전체 파이프라인이기도 하다. 서비스를 극대화하기 위해 모델에 들어가는 인풋 정보들을 어떻게 구성할지, 그리고 그걸 시스템 엔지니어링 관점에서 어떻게 효율적으로 주입할지 고민했다. 아웃풋 역시 어떤 모델들을 조합하고 어떤 파이프라인을 구축해야 유저에게 최적의 속도로 전달될지 이것저것 따져보면서 닫혀있던 시야가 다시 한번 넓어지는 기분이었다.

본선에는 1000팀이 넘게 지원했다고 들었는데 다행히 올라갈 수 있었고, 카카오 AI 캠퍼스에서 1박 2일 동안 개발을 진행하게 되었다. 함께한 팀원들도 일하다 모인 상태였음에도 프로덕트를 만드는 데 있어 열정이 대단하다는 걸 느꼈었다.
예전에 참여했던 해커톤을 떠올려보면 가장 어려웠던 건 제한된 시간 안에 기능을 구현하는 일이었다. 그런데 지금은 AI가 개발 과정에 자연스럽게 녹아들면서 구현 속도 자체는 훨씬 빨라졌다. 대신 그만큼 기대 수준도 높아졌다.



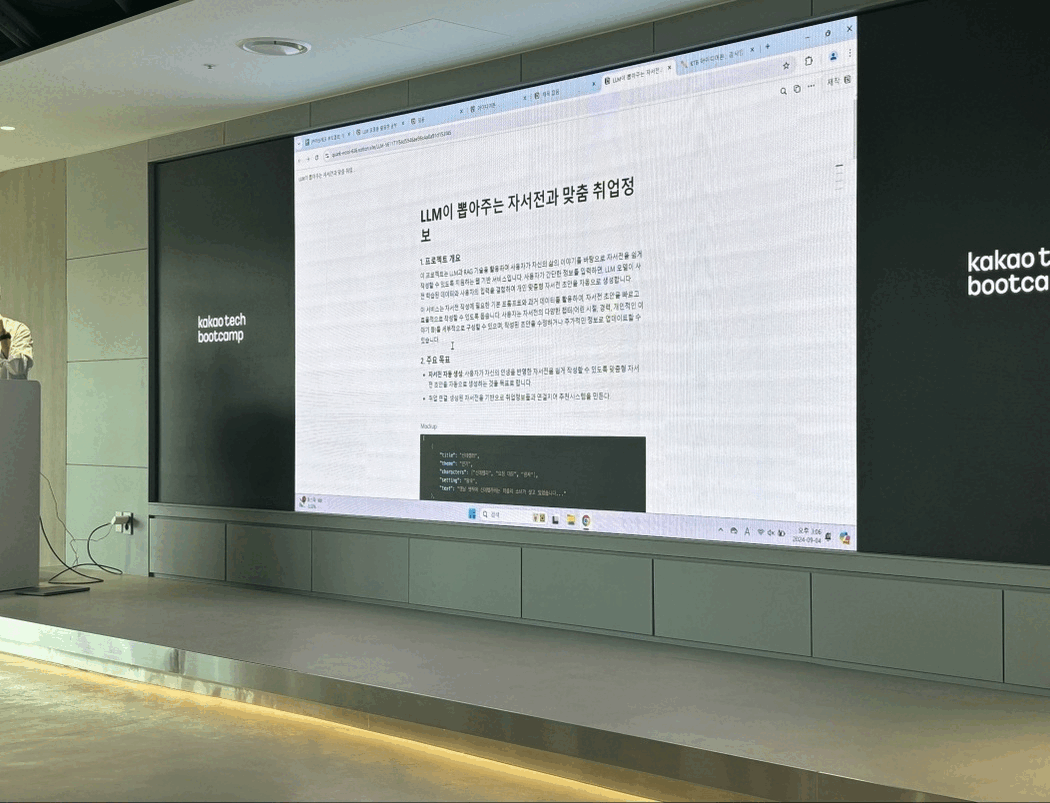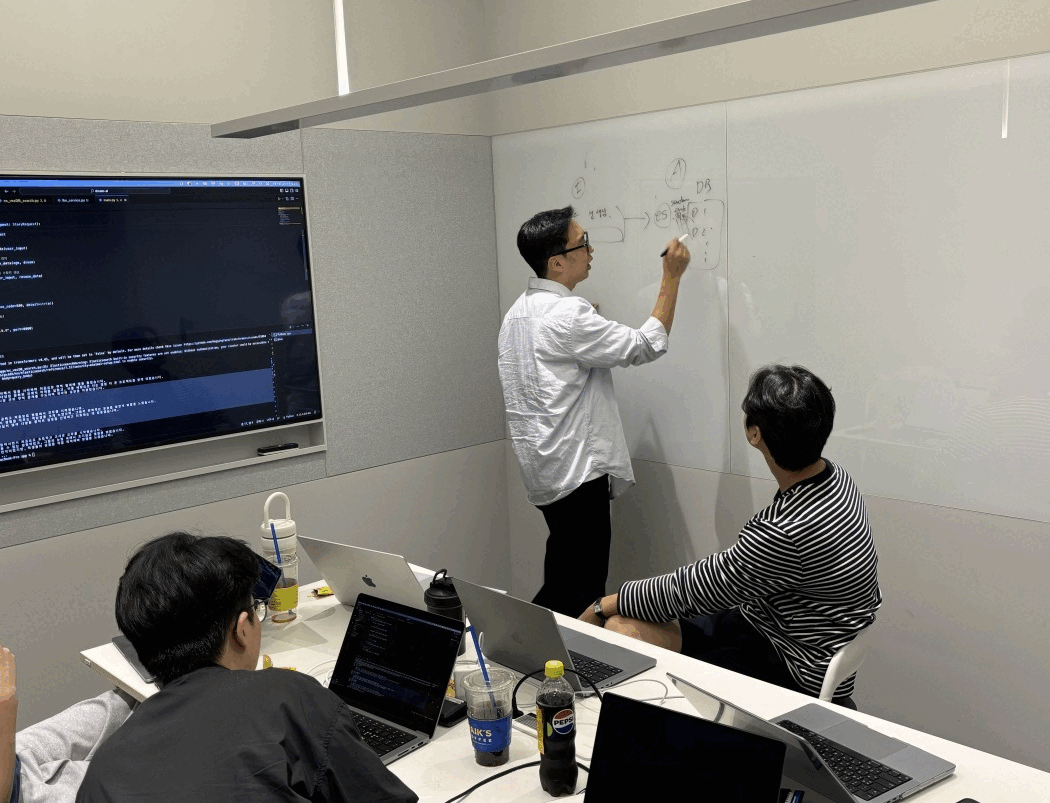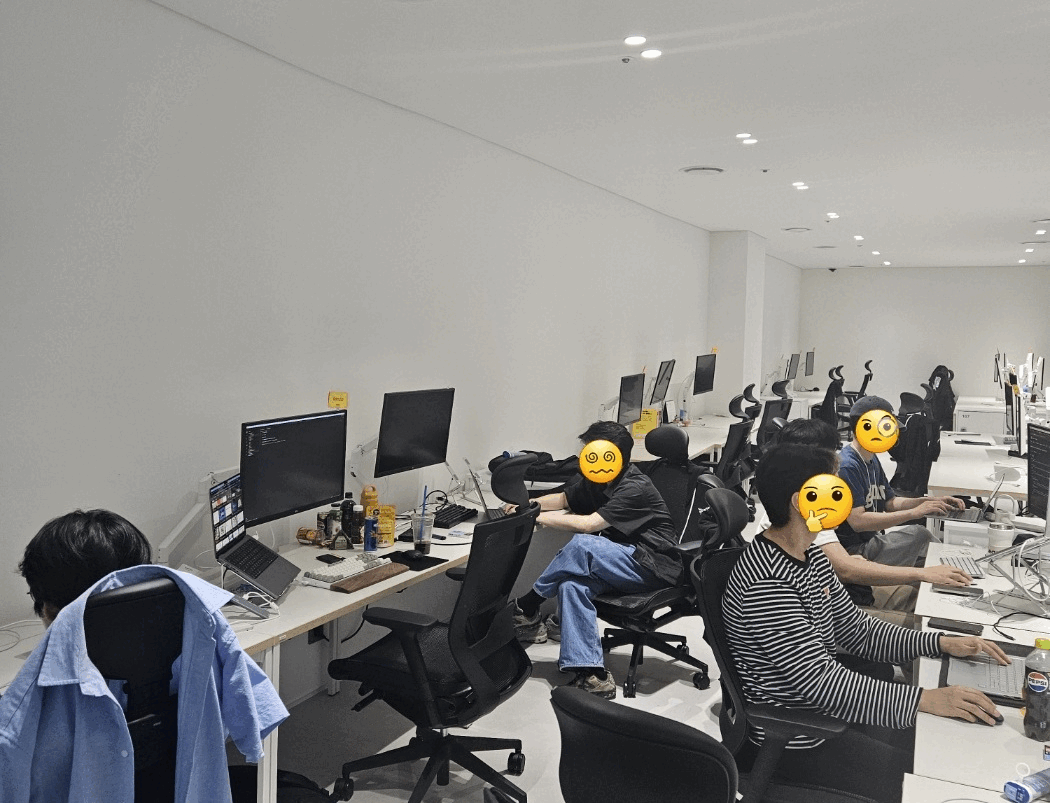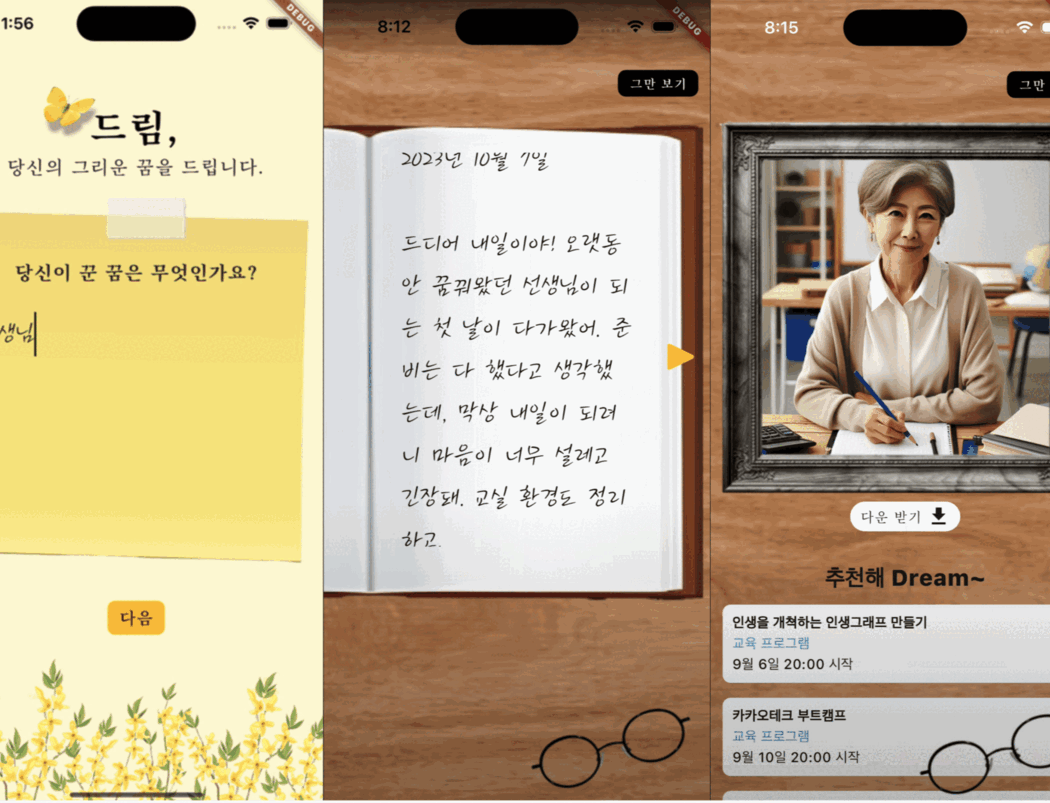
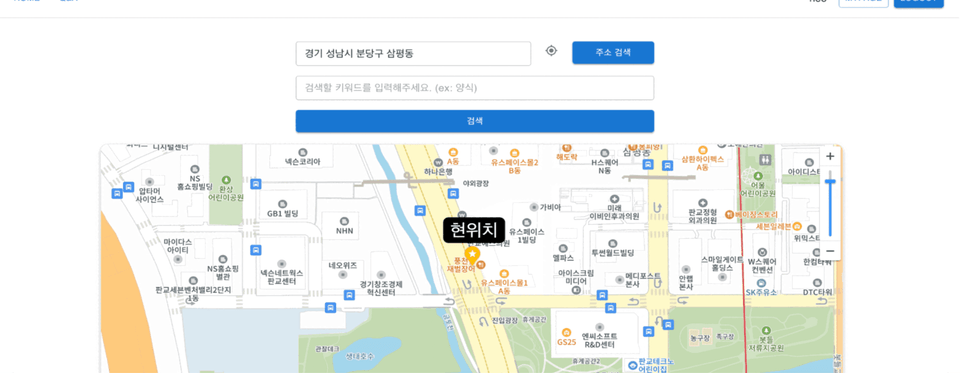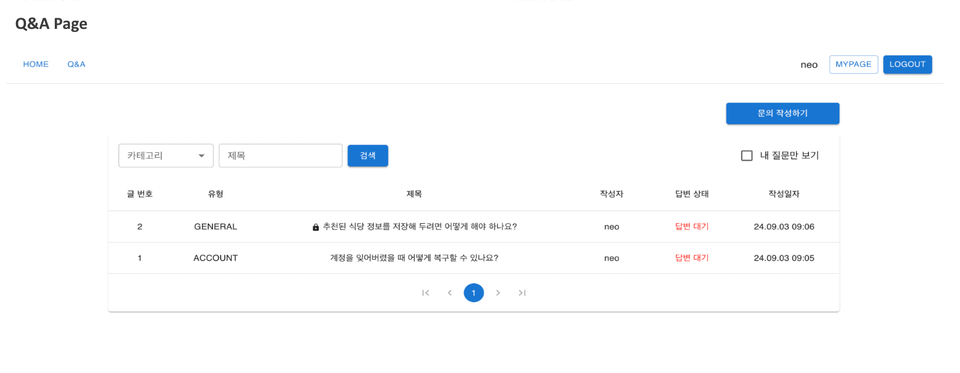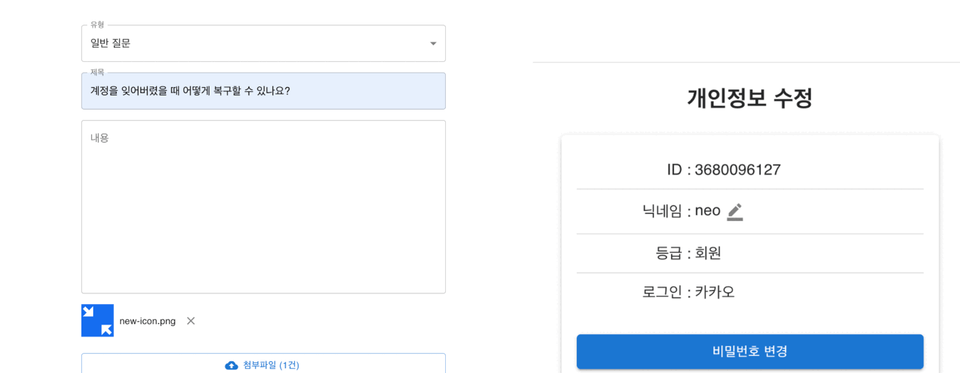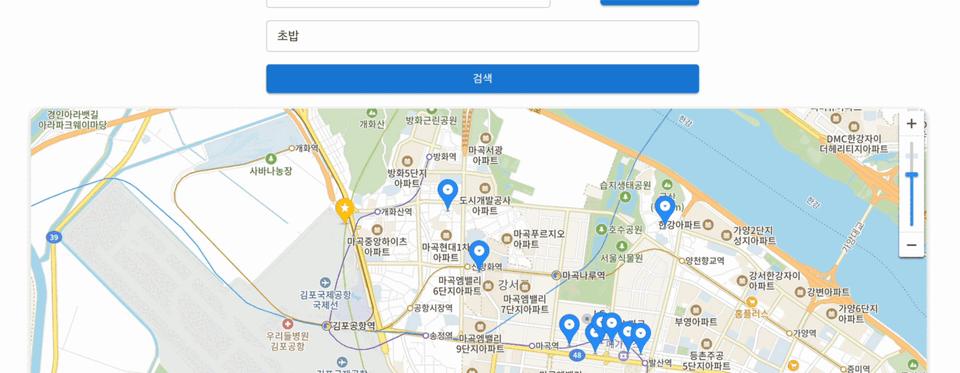
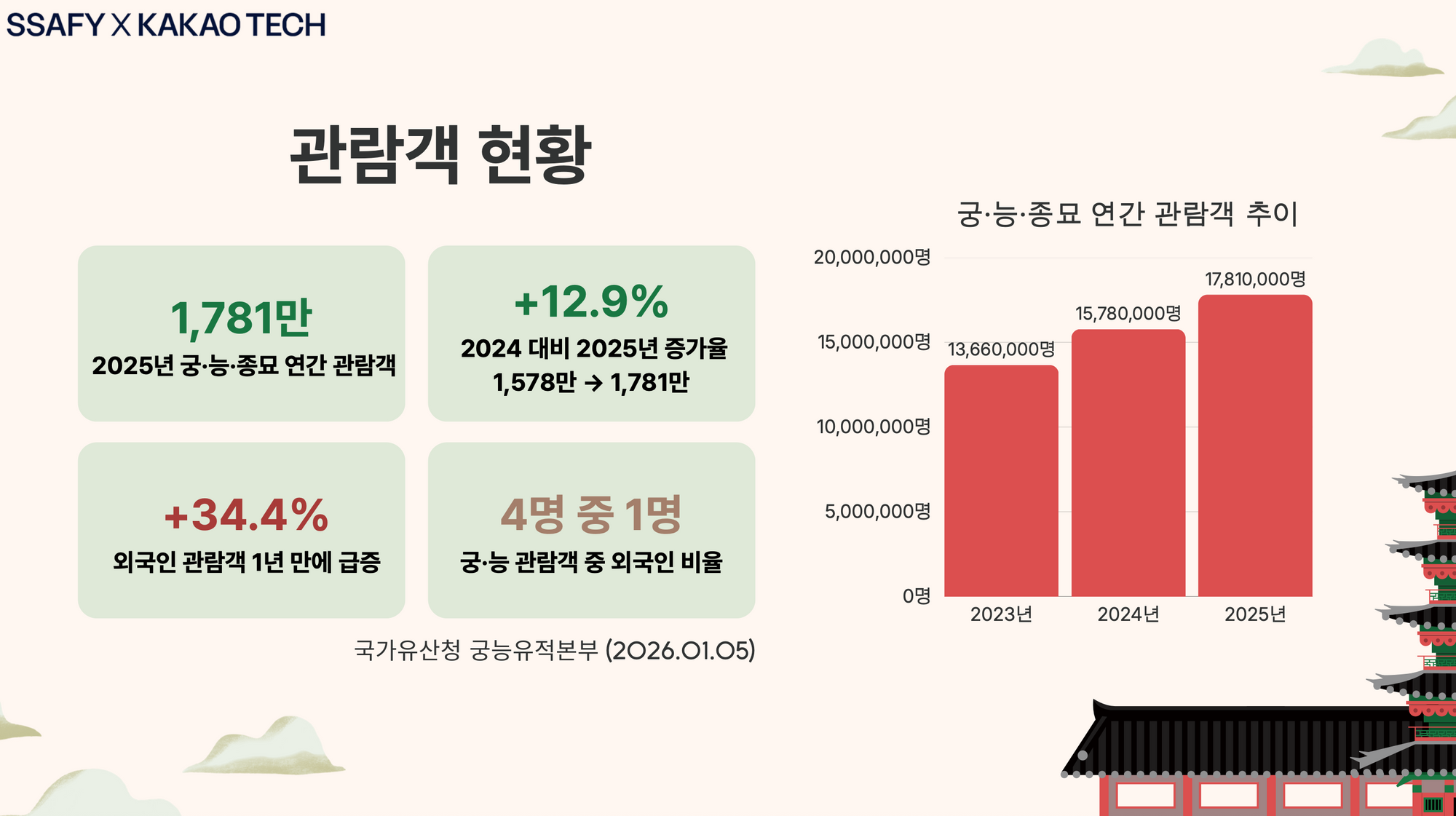
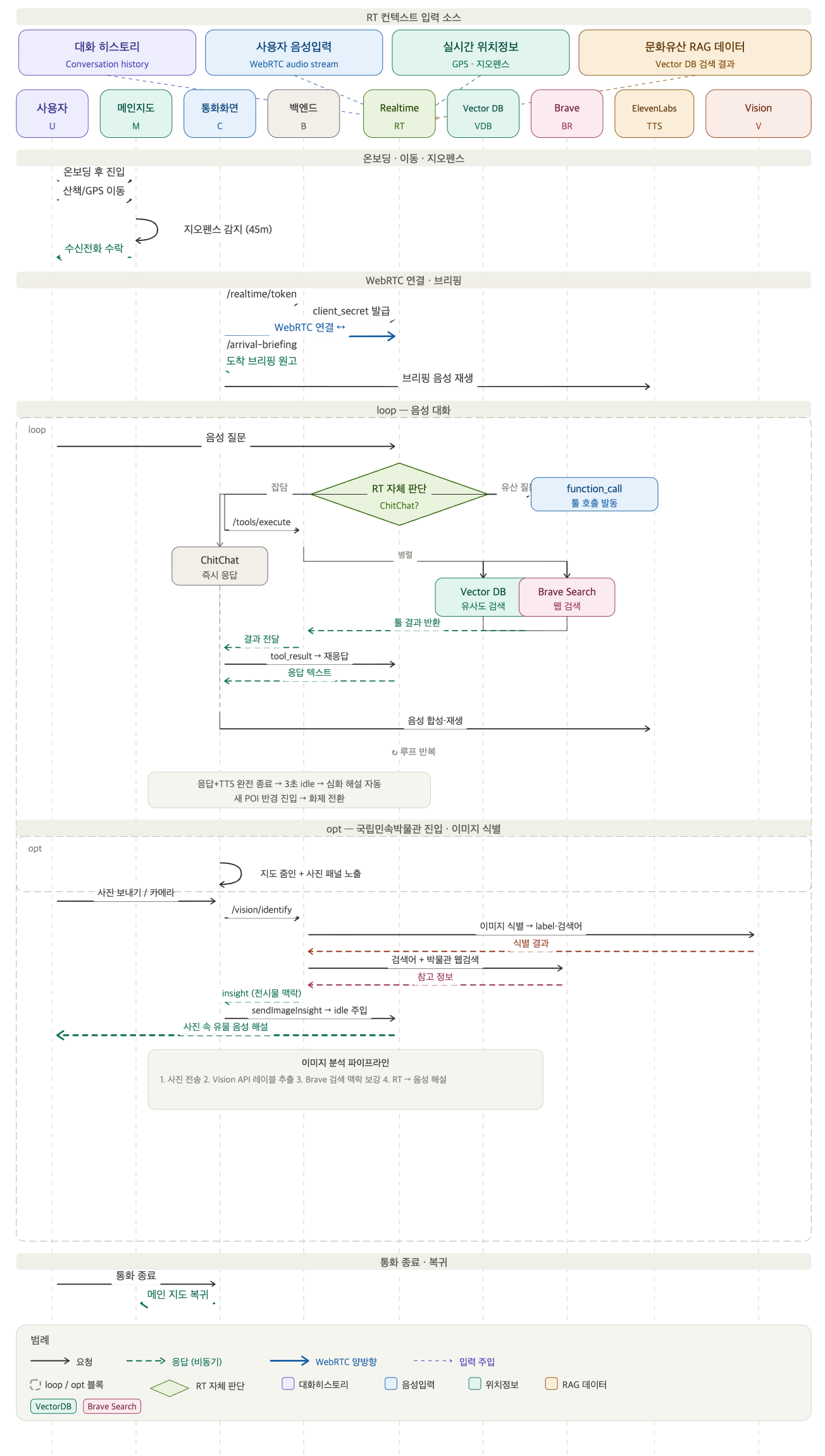
우리가 만든 서비스는 위치 기반 AI 문화유산 해설 서비스였다. 기존의 문화재 안내 서비스들은 사용자가 직접 고정된 메시지를 듣거나 실제 사람이 하는 도슨트를 듣는 것이 일반적이지만, 우리는 이 제약을 깨고 싶었다. 그래서 자유도 높은 위치 기반 음성 챗 서비스와, GPS가 닿지 않는 실내 공간을 보완하기 위해 이미지를 통한 실내 가이드 서비스를 잡았다.
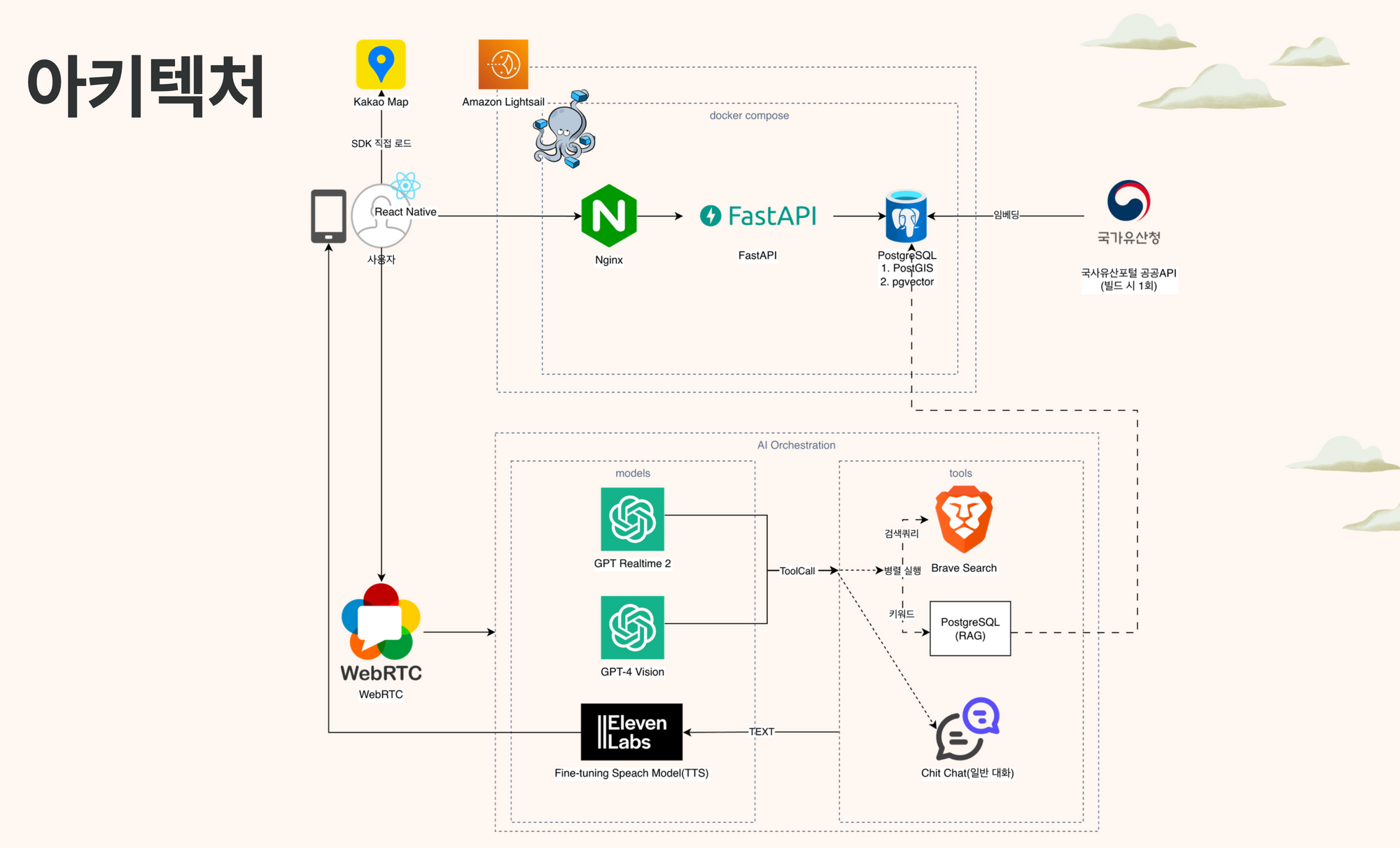
우선 정확한 문화재 정보 서빙을 위해 국가유산청 API를 연동했고, 현실적인 데이터 공백이나 실시간 외부 정보를 커버하기 위해 웹 서치를 LLM의 툴로 에이전트 아키텍처에 내장했다. 보통 RAG 시스템을 구축할 때 청킹 전략이 핵심 포인트가 되곤 하지만, 국가유산청 데이터는 대부분 건당 char기준 1K 미만이었고 활용한 모델의 컨텍스트 윈도우는 128K로 충분히 넉넉했기 때문에 정보 손실을 막기 위해 청킹 없이 원본 데이터를 그대로 벡터 DB에 저장했다.
개발하면서 가장 고생했던 포인트는 WebRTC 환경에서 우회 프로토콜을 설계하는 작업이었다. 개발 편의성과 레이턴시만 생각하면 WebRTC로 Realtime 모델을 직접 호출해 단일 프로토콜을 유지하는 게 베스트다. 하지만 우리 서비스의 셀링 포인트중 하나는 침착맨이나 하츄핑 같은 파인튜닝된 TTS 모델을 활용해 유저에게 친근한 보이스로 서빙하는 것이었다.
이를 구현하기 위해 WebRTC 안에서 인풋 음성 스트림은 지속적으로 연결되게 두고, 백엔드단은 조금 틀어서 설계했다. 인풋 음성이 들어오면 내부적으로는 텍스트 기반으로 에이전트가 돌고, 이를 ElevenLabs API를 통해 POST 요청으로 받은 값을 음성 파일로 실행시킨 뒤, 내부 status 값으로 세션을 실시간 업데이트하는 방식을 썼다. 유저 입장에서는 연결 끊김 이슈 없이 지속적으로 음성 서비스를 받을 수 있도록 프로토콜을 매끄럽게 이어붙이는 작업이 생각보다 까다로웠다. 이런 점들을 고려해가며 치열하게 개발한 덕분에 우리끼리 만족할 만한 안정성 있는 서비스를 만들어낼 수 있었다.
물론 짧은 시간 내에 해결하지 못한 아쉬움도 있다. 유저의 인풋이 길거나 모델이 내뱉은 아웃풋이 길 때, 파인튜닝된 TTS 모델을 한 번 더 거쳐야 하므로 발생하는 레이턴시 이슈가 있었다. 또 프림블 기능 때문에 오디오 버퍼 타이밍이 안 맞아 음성이 간헐적으로 끊기는 케이스들을 완벽하게 잡기란 쉽지 않았다.


우리가 구현해낸 안정성과 퀄리티에 스스로 꽤 만족했고 당연히 수상할 거라는 생각도 내심 했었다. 하지만 아쉽게도 상을 받지는 못했다. 모든 일이 그러하듯 치열한 필드에는 운과 간절함의 차이가 존재한다는 것, 그리고 기술적으로 잘 풀었다고 해서 결코 오만하면 안 된다는 걸 다시 한번 배웠다. 결과를 깔끔하게 승복하고 멋진 결과물을 보여준 다른 수상 팀들에게 축하를 건내보려 했다ㅠ. 다음에 또 해커톤을 할지는 모르겠지만 차후를 기약해본다. 졌잘싸.....ㅋㅋㅋㅋ
오랜만에 밤새 가며 개발하는 게 체력적으로 힘에 부치기도 했다. 하지만 머리를 맞대고 무언가를 만들어내는 행위 자체가 나라는 사람을 자극하고 기쁘게 만든다는 걸 다시 한번 느꼈다. 함께 고생해 준 우리 팀원들 모두 앞으로 더 좋은 개발자와 연구자로 성장하길 빈다.