Search Engines - Text Representation

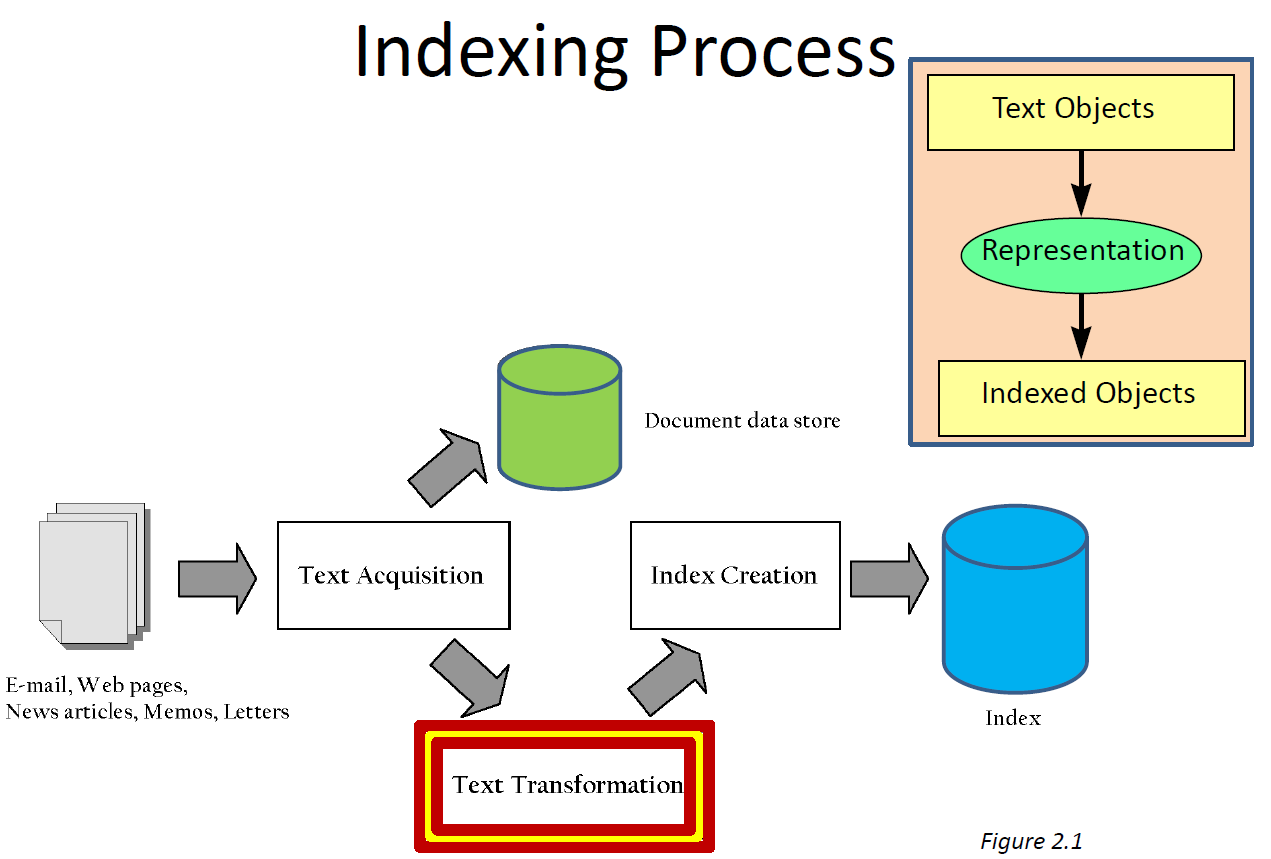
Tokenizing
-
Forming words from sequence of characters
-
Surprisingly complex in English, can be harder in other languages
-
Early IR systems:
– any sequence of alphanumeric characters of length 3 or more
– terminated by a space or other special character
– upper-case changed to lower-case -
Example:
–> “We’d like to see Illinois become a right-to-work state,” he said.
–> we d like to see illinoisbecome a right to work state he said -
Too simple for search applications or even large-scale experiments
-
Why?
– Too much information lost
– Small decisions in tokenizing can have major impact on effectiveness of some queries
Tokenizing Problems
- Small words can be important in some queries, usually in combinations
- xp, ma, pm, bene king, el paso, master p, gm, j lo, world war II
- Both hyphenated and non-hyphenated forms of many words are common
– Sometimes hyphen is not needed (e-bay, wal-mart, active-x, cd-rom, t-shirts)
– At other times, hyphens should be considered either as part of the word or a word separator (winston-salem, mazdarx-7, e-cards, pre-diabetes, t-mobile, spanish-speaking )
– Data base, data-base, database 10 - Special characters are an important part of tags, URLs, code in documents
- Capitalized words can have different meaning from lower case words
– Bush, Apple, Trump - Apostrophes can be a part of a word, a part of a possessive, or just a mistake
– rosieo'donnell, can't, don't, 80's, 1890's, men's straw hats, master's degree, england'sten largest cities, shriner's - Numbers can be important, including decimals
– iphone14, top 10 courses, 9/11, united 93, quicktime7.7.9, WMUA 91.1, 867-5309, cs446 - Periods can occur in numbers, abbreviations, URLs, ends of sentences, and other situations
– I.B.M., Ph.D., cs.umass.edu, 192.168.0.1, F.E.A.R. - Note: tokenizing steps for queries must be identical to steps for documents
Tokenizing Process
- First step is to use parser to identify appropriate parts of document to tokenize
- Candefer complex decisions to other components
– word is any sequence of alphanumeric characters, terminated by a space or special character, with everything converted to lower-case
– everything indexed
– example: 92.3 → 92 3 but expect search to find documents with 92 and 3 adjacent
– incorporate some rules to reduce dependence on query transformation components - Not that different than simple tokenizing process used in past
- Examples of rules used with TREC
– Apostrophes in words ignored (squeezed out) -> o’connor→ oconnor
– Periods in abbreviations ignored with one-character tokens, else treated as space ( I.B.M. → ibm / Ph.D. → ph d )
Stopping
- Function words (determiners, prepositions) have little meaning on their own
- High occurrence frequencies
- Treated as stopwords(i.e., removed)
– reduce index space, improve response time, improve effectiveness - Stopwordscan be important in combinations
– e.g., “to be or not to be” or “the The” - Stopwordlist can be created from high-frequency words or based on a standard list
- Lists are customized for applications, domains, and even parts of documents
– “click” and “here” good stopwordsfor anchor text - Best policy is often to index all words in documents, make decisions about which words to use at query time
Stemming
- Many morphological variations of words
– inflectional(plurals, tenses)
– derivational(making verbs into nouns etc.) - In most cases, these have the same or very similar meanings
- Stemmers attempt to reduce morphological variations of words to a common stem
– usually involves removing suffixes
– Can include exceptions like mice → mouse - Can be done at indexing time or as part of query processing (like stopwords)
- Generallya small but significant effectiveness improvement
– can be crucial for some languages
– e.g., 5-10% improvement for English, up to 50% in Arabic
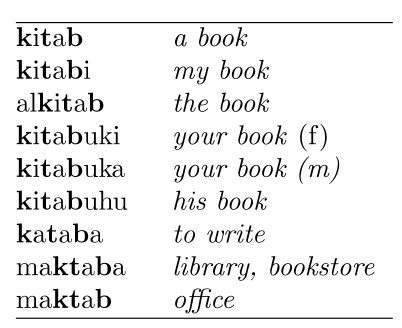
- Two basic types
– Dictionary-based: uses lists of related words
– Algorithmic: uses program to determine related words - Algorithmic stemmers
– suffix-s: remove ‘s’ endings, assuming plural-e.g., cats → cat, lakes → lake, wiis→ wii
-Many false negatives: supplies → supplie(cf. supply)
-Some false positives: ups → up
Porter Stemmer
- Algorithmic stemmer used in IR experiments since the 70s
- Series of rules designed to remove the longest possible suffix at each step
- Effective in IR system evaluations
- Produces stems not words
- Makes a number of errors and difficult to modify


Text Statistics
Zipf’s Law
- Distribution of word frequencies is very skewed
– a few words occur very often, many words hardly ever occur
– e.g., two most common words (“the”, “of”) make up about 10% of all word occurrences in text documents
– e.g., almost half of the terms occur once - Zipf’s“law” (more generally, a “power law”):
– observation that rank (r) of a word times its frequency (f) is approximately a constant (k) / assuming words are ranked in order of decreasing frequency
– i.e., r·f≈k or r·Pr≈c, where Pr is probability of word occurrence and c≈ 0.1 for English
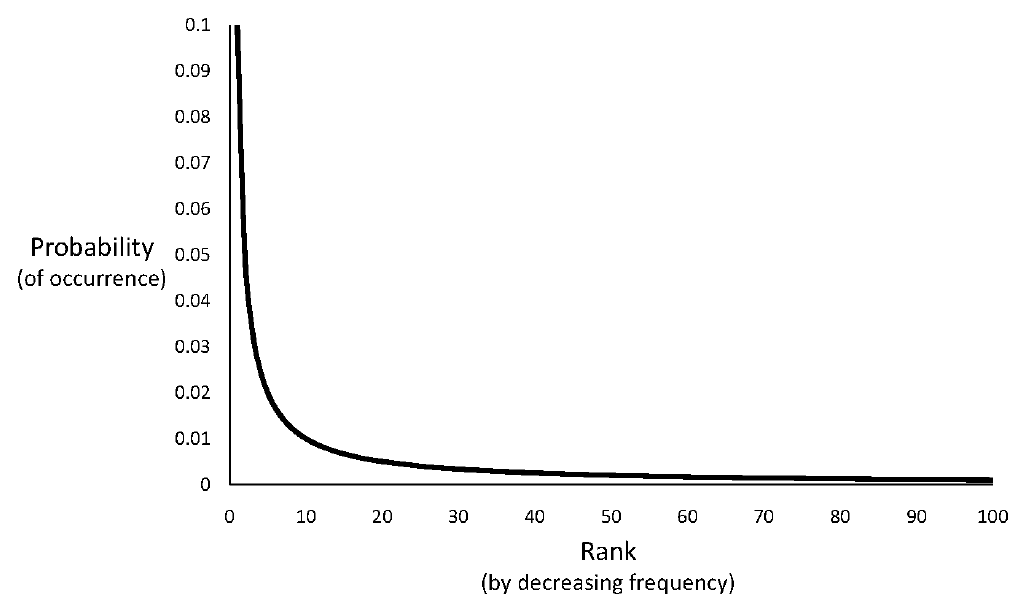
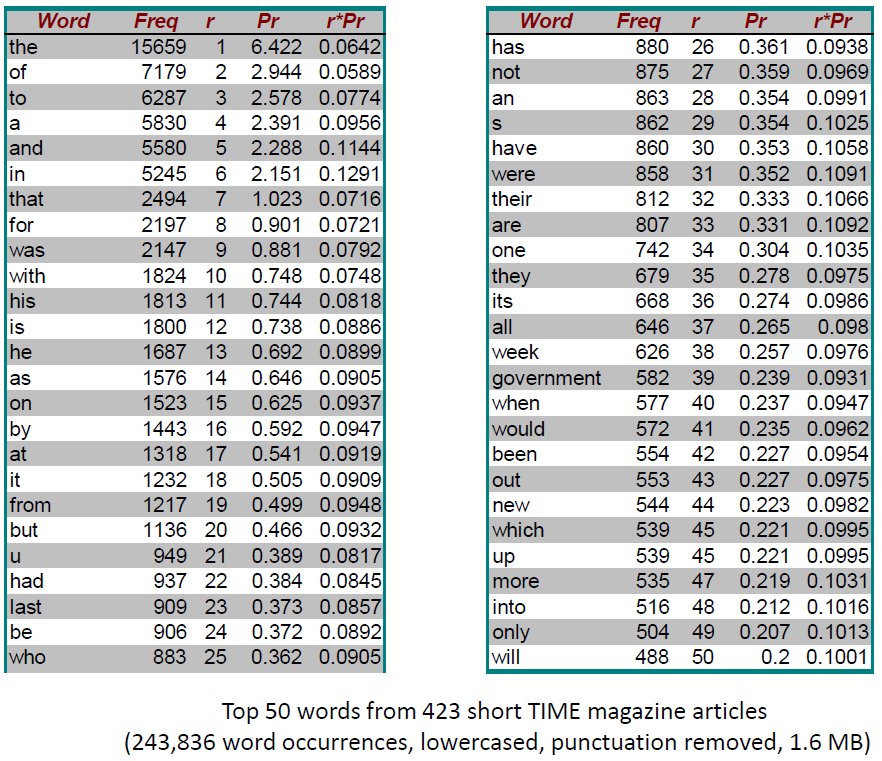
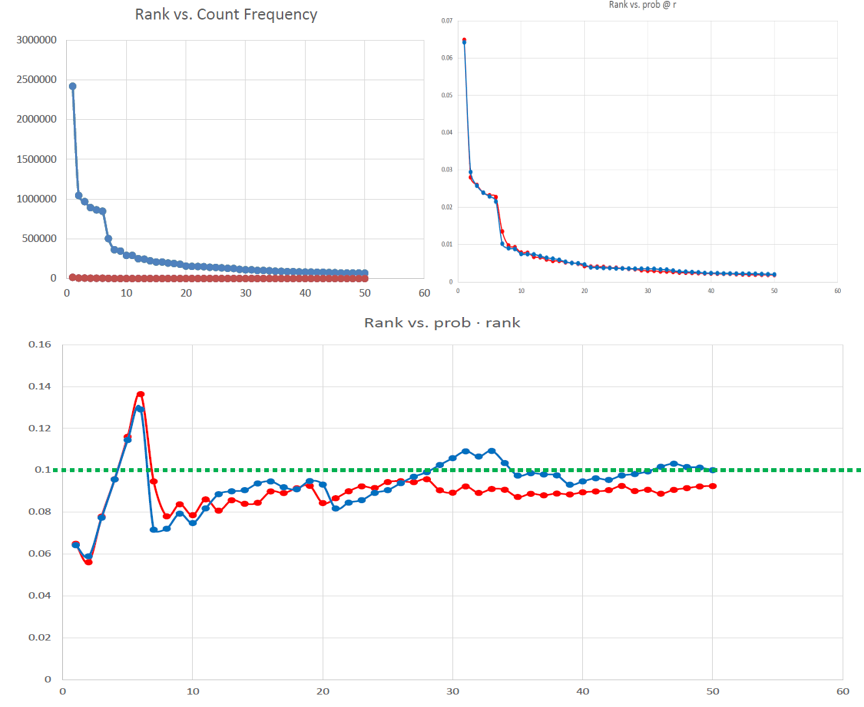
What else does Zipf tell us?
- We know that the most common word
accounts for about 10% of the total
occurrences
– r=1, c=0.1, so P(r) = 0.1/1 = 10% - How often does the second most frequent
term occur? r*Pr = c, 2pr= 0.1 -> Pr = 0.12 = 0.05 - How many words occur 10 times? 3 times ?

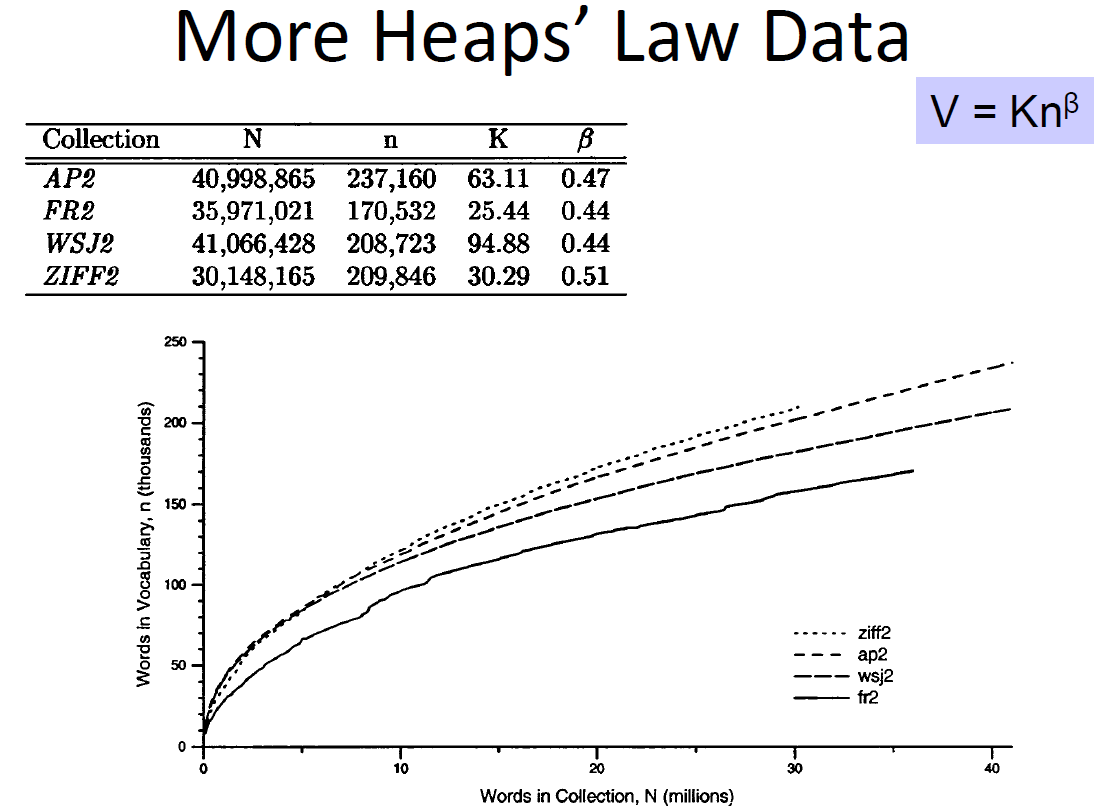
Heaps’ Law
- Predictions for TREC collections are accurate for large numbers of words
– e.g., first 10,879,522 words of the AP89 collection scanned
– prediction is 100,151 unique words
– actual number is 100,024 - Predictions for small numbers of words (i.e. < 1000) are much worse
 IlMinCho
IlMinCho– Tokenization (spaces or fancy)
– Stopping (not or with a list)
– Stemming (not or Porter steps 1a-1c)
– Input (gzip!): train, S&S
– Output: Prefix / Tokens, heaps, stats
Analysis
- Run your program with fancy tokenization, stopping, and Porter stemming on sense-and-sensibility.gz and look at the -tokens.txt -stats.txt file to see the most frequent terms from Sense and Sensibility. Are the top terms relevant to the story or do they seem like everyday words that aren't particularly to the novel? Support your answer with examples. You may find it useful to skim the summary on Wikipedia to know what words are part of the story.
Based on my data, the most frequently found word was her at number 2561. In fact, it is difficult to find a big connection because it is a word that appears in most novels, but in this novel, two sisters named Elinor and Marianne appear as the main characters, and considering this information, it can be inferred that a woman is the main character.
- Are there any of those top terms that should have been stopwords? Do the top terms or the list of all tokens suggest any changes to the tokenizing or stemming rules? What are they and why should they be made?
Among the top terms, words such as i, not, you, had, but, have, all, so, my, which, could, no... are unnecessary words to grasp the contents of the novel. These are words that can appear in any novel you read, so we don't need them to get information about the content. However, stopwords need to be modified for the purpose you are trying to get via stat. If we add the stopwords mentioned above, we get a value that ranks the names of characters like Elinor and Marianne higher. In addition, it would be nice not to add additional tokenizing or stemming rules.
- Figure 4.4. in the textbook (p. 82) displays a graph of vocabulary growth for the TREC GOV2 collection. Create a similar graph for Sense and Sensibility and upload an image of your graph. Note that you should be able to use the -heaps.txt file to generate the graph.
This is a graph using the heap data of Sense and Sensibility, the x-axis is the number of tokens, and the y-axis shows the number of unique tokens.
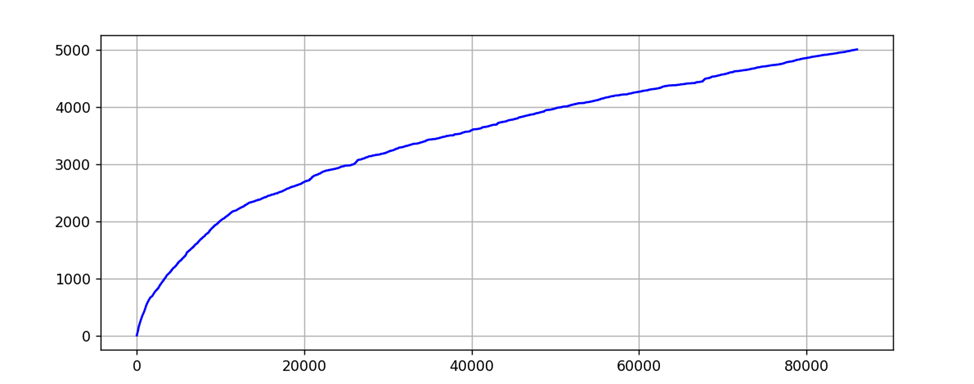
- Does Sense and Sensibility follow Heaps Law? Why do you think so or think not?
This follows the heap's law. Looking at the data, as the number of tokens increases, the number of unique tokens continues to increase. And since the increasing rate is gradually decreasing, it can be seen as a case of heap's law. Additionally, looking at the graph, it increases relatively steeply at the beginning and gradually flattens as the number of tokens increases, which is a model of heap's law.
Reference: Prof. James Allan



