Search Engines - Information Retrieval

Information Retrieval
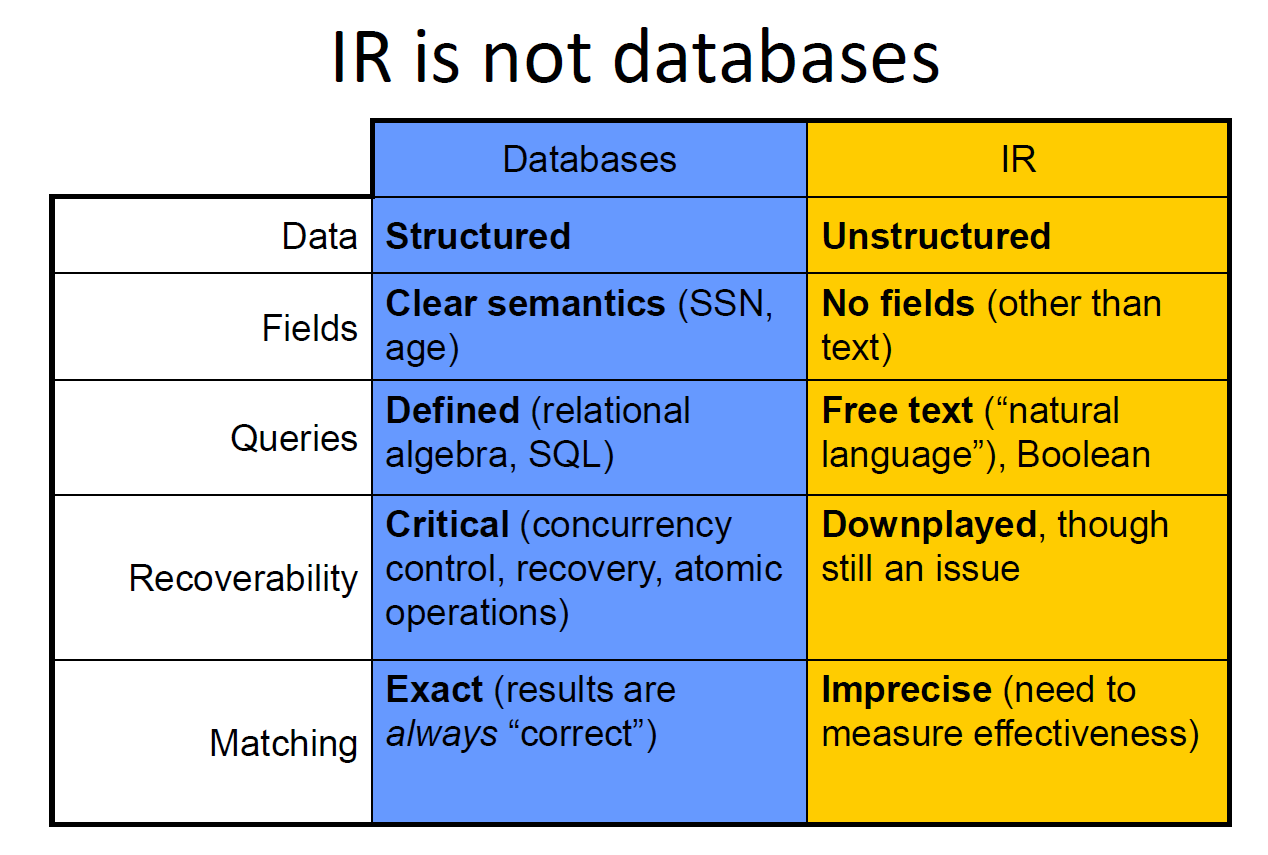
“Information retrieval is a field concerned with the structure, analysis, organization, storage, searching, and retrieval of information.”(Salton, 1968)
- General definition that can be applied to many types of information and search applications
- Primary focus of IR since the 50s has been on textand documents
Basic Approach to IR
- Most (but not all!) successful approaches are statistical
- Directly, or an effort to capture and use probabilities
- Why not natural language understanding?
- i.e., computer understands docs and query and matches them
- State of the art is brittle in unrestricted domains
- Can be highly successful in predictable settings, though
- ChatGPTsuggests things are improving, but it still makes plenty of mistakes (and doesn’t really “understand” anything)
- Could use manually assigned headings
- e.g., Library of Congress headings, Dewey Decimal headings
- Hard to predict what headings are “interesting”
- Expensive and human agreement is not good
“Bag of Words”
- An effective and popular approach
- Compares words without regard to order
- Consider reordering words in a headline
- Random: beating takes points falling another Dow 355
- Alphabetical: 355 another beating Dow falling points
- “Interesting”: Dow points beating falling 355 another
- Actual: Dow takes another beating, falling 355 points
Statistical language model
-
Document comes from a topic
-
Topic (unseen) describes how words appear in documents on the topic
-
Use document to guesswhat the topic looks like
-Words common in document are common in topic
-Words not in document much less likely to be in the topic
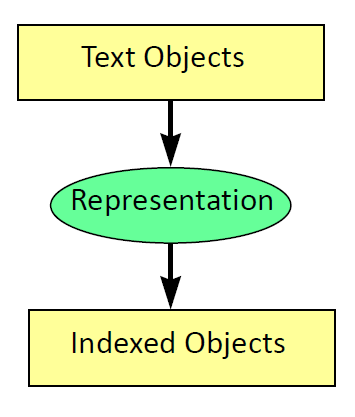
-
Assign probability to words based on document
- P(w|Topic) ≈P(w|D) = tf(w,D) / len(D)
-
Index estimated topics
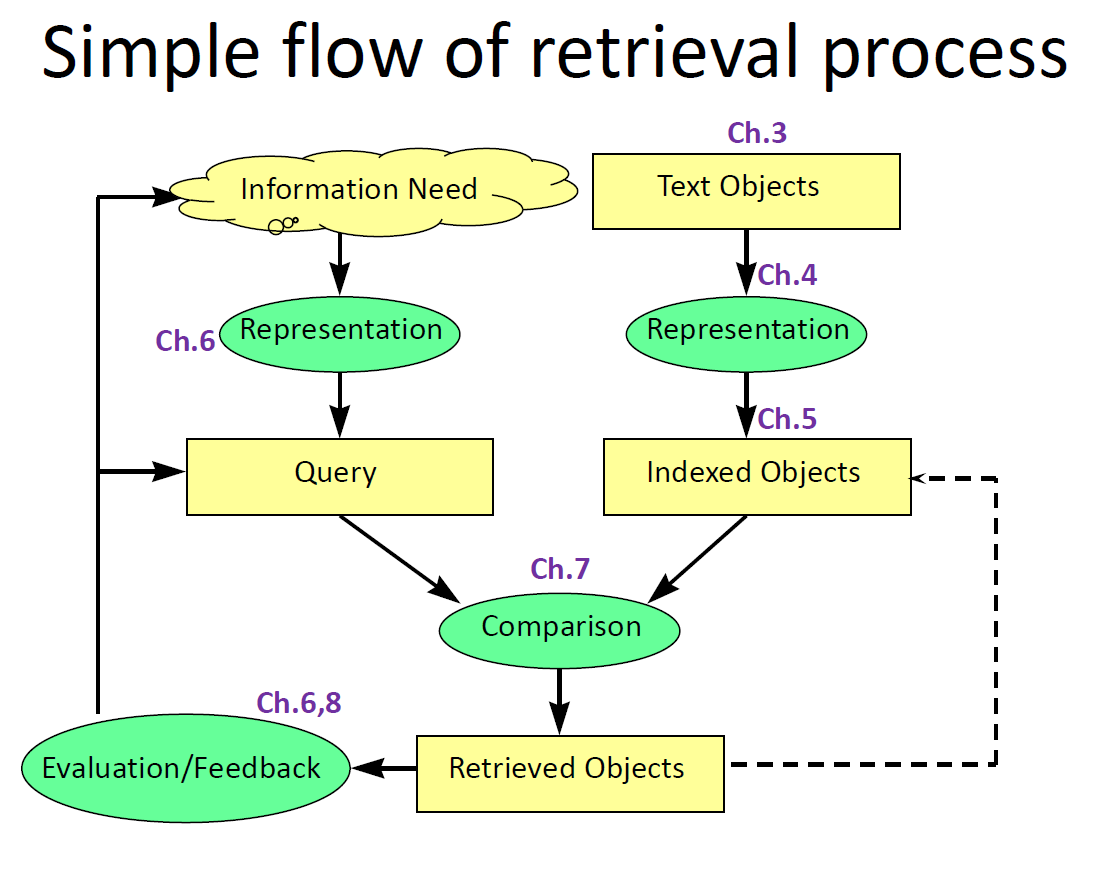
What does LM look like implemented?
-
Hypothesis of statistical language model
– Documents with topic models that are highly likely to generate the query are more likely to be relevant (to query) -
Index collection in advance (chs. 3&4)
– Convert documents into set of P(ti|D)
– Store in an appropriate data structure for fast access -
Query arrives (ch.6&7)
– Convert it to set P(qi|D)
– Calculate P(Q|TD) for all documents
– Sort documents by their topics’ probability
– Present ranked list -
Generally good results (ch.8) though not with version of the model that is this simple (ch.5)
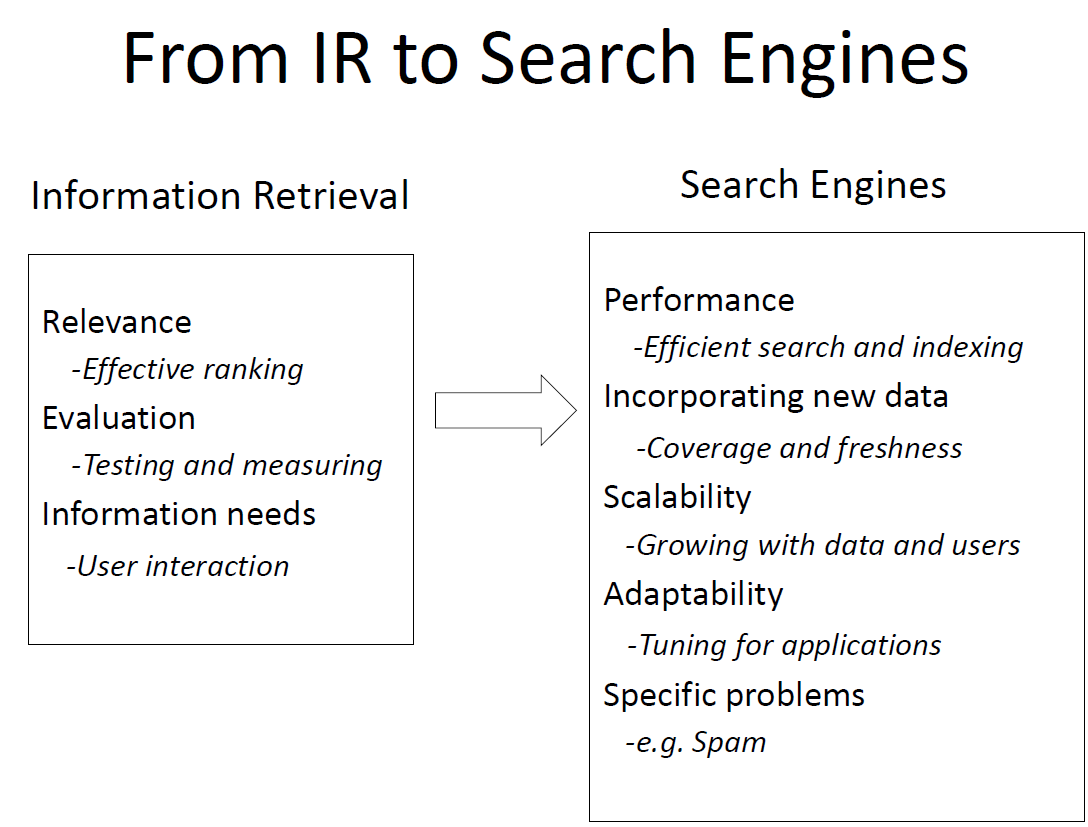
Some issues that arise in IR
-
Text representation
– what makes a “good” representation?
– how is a representation generated from text?
– what are retrievable objects and how are they organized? -
Representing information needs
– what is an appropriate query language?
– how can interactive query formulation and refinement be supported? -
Comparing representations
– what is a “good” model of retrieval?
– how is uncertainty represented? -
Evaluating effectiveness of retrieval
– what are good metrics?
– what constitutes a good experimental test bed?
Reference: Prof. James Allan



